
The rapid growth of data-intensive use cases such as simulations, streaming applications (like IoT and sensor feeds), and unstructured data has elevated the importance of performing fast database operations such as writing and reading data—especially when those applications begin to scale. Almost any component in a system can potentially become a bottleneck, from the storage and network layers through the CPU to the application GUI.
As we discussed in “Optimizing metadata performance for web-scale applications,” one of the main reasons for data bottlenecks is the way data operations are handled by the data engine, also called the storage engine—the deepest part of the software stack that sorts and indexes data. Data engines were originally created to store metadata, the critical “data about the data” that companies utilize for recommending movies to watch or products to buy. This metadata also tells us when the data was created, where exactly it’s stored, and much more.
Inefficiencies with metadata often surface in the form of random read patterns, slow query performance, inconsistent query behavior, I/O hangs, and write stalls. As these problems worsen, issues originating in this layer can begin to trickle up the stack and show to the end user, where they can show in form of slow reads, slow writes, write amplification, space amplification, inability to scale, and more.
New architectures remove bottlenecks
Next-generation data engines have emerged in response to the demands of low-latency, data-intensive workloads that require significant scalability and performance. They enable finer-grained performance tuning by adjusting three types of amplification, or writing and re-writing of data, that are performed by the engines: write amplification, read amplification, and space amplification. They also go further with additional tweaks to how the engine finds and stores data.
Speedb, our company, architected one such data engine as a drop-in replacement for the de facto industry standard, RocksDB. We open sourced Speedb to the developer community based on technology delivered in an enterprise edition for the past two years.
Many developers are familiar with RocksDB, a ubiquitous and appealing data engine that is optimized to exploit many CPUs for IO-bound workloads. Its use of an LSM (log-structured merge) tree-based data structure, as detailed in the previous article, is great for handling write-intensive use cases efficiently. However, LSM read performance can be poor if data is accessed in small, random chunks, and the issue is exacerbated as applications scale, particularly in applications with large volumes of small files, as with metadata.
Speedb optimizations
Speedb has developed three techniques to optimize data and metadata scalability—techniques that advance the state of the art from when RocksDB and other data engines were developed a decade ago.
Compaction
Like other LSM tree-based engines, RocksDB uses compaction to reclaim disk space, and to remove the old version of data from logs. Extra writes eat up data resources and slow down metadata processing, and to mitigate this, data engines perform the compaction. However, the two main compaction methods, leveled and universal, impact the ability of these engines to effectively handle data-intensive workloads.
A brief description of each method illustrates the challenge. Leveled compaction incurs very small disk space overhead (the default is about 11%). However, for large databases it comes with a huge I/O amplification penalty. Leveled compaction uses a “merge with” operation. Namely, each level is merged with the next level, which is usually much larger. As a result, each level adds a read and write amplification that is proportional to the ratio between the sizes of the two levels.
Universal compaction has a smaller write amplification, but eventually the database needs full compaction. This full compaction requires space equal or larger than the whole database size and may stall the processing of new updates. Hence universal compaction cannot be used in most real-time high performance applications.
Speedb’s architecture introduces hybrid compaction, which reduces write amplification for very large databases without blocking updates and with small overhead in additional space. The hybrid compaction method works like universal compaction on all the higher levels, where the size of the data is small relative to the size of the entire database, and works like leveled compaction only in the lowest level, where a significant portion of the updated data is kept.
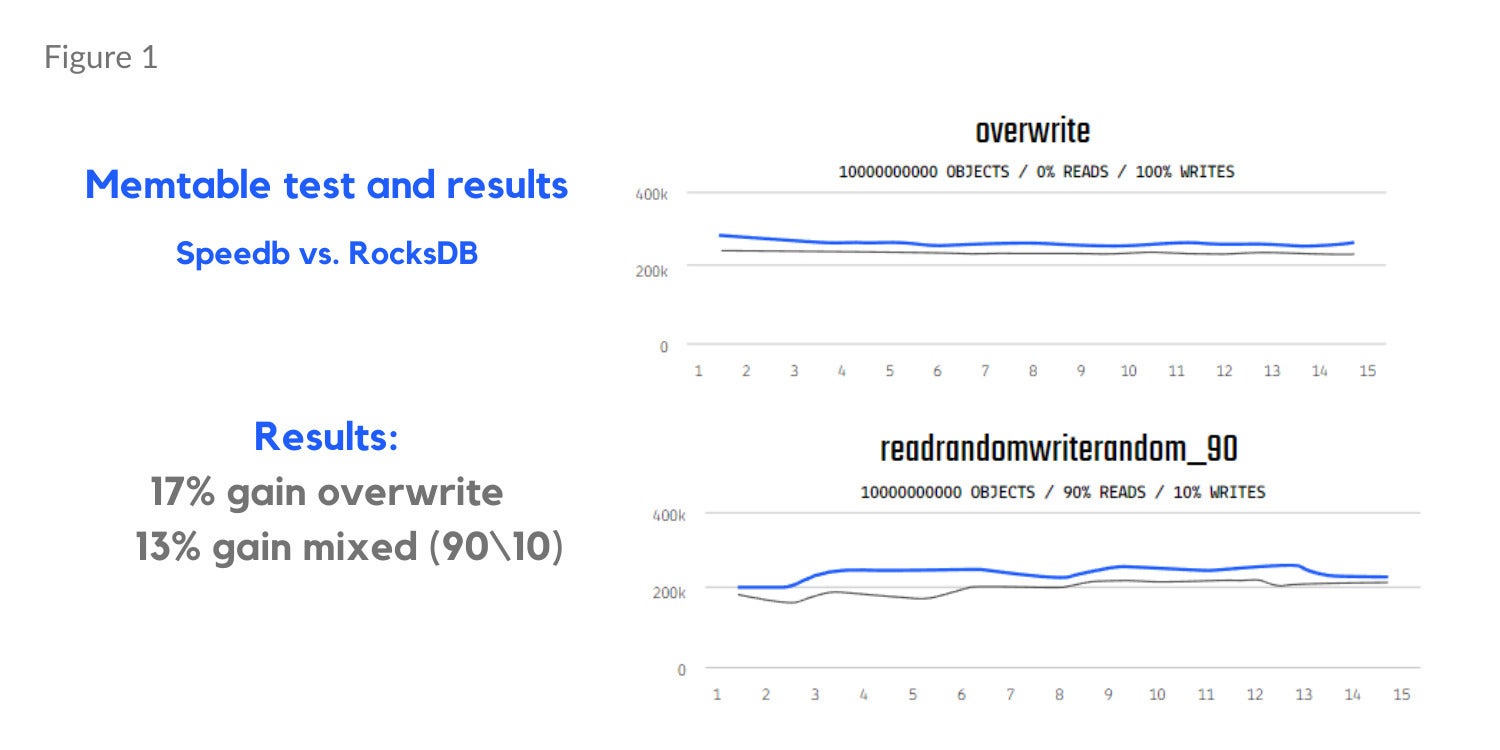
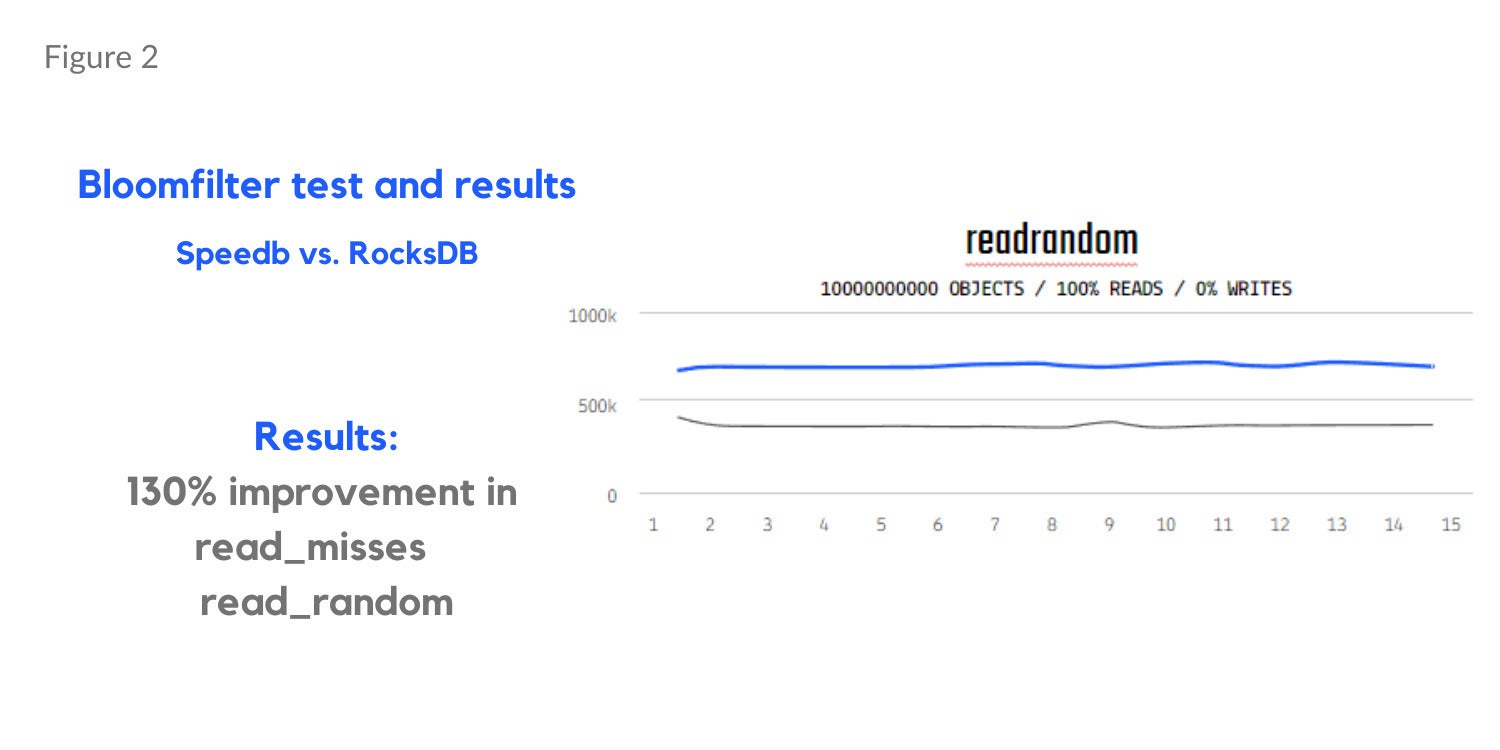
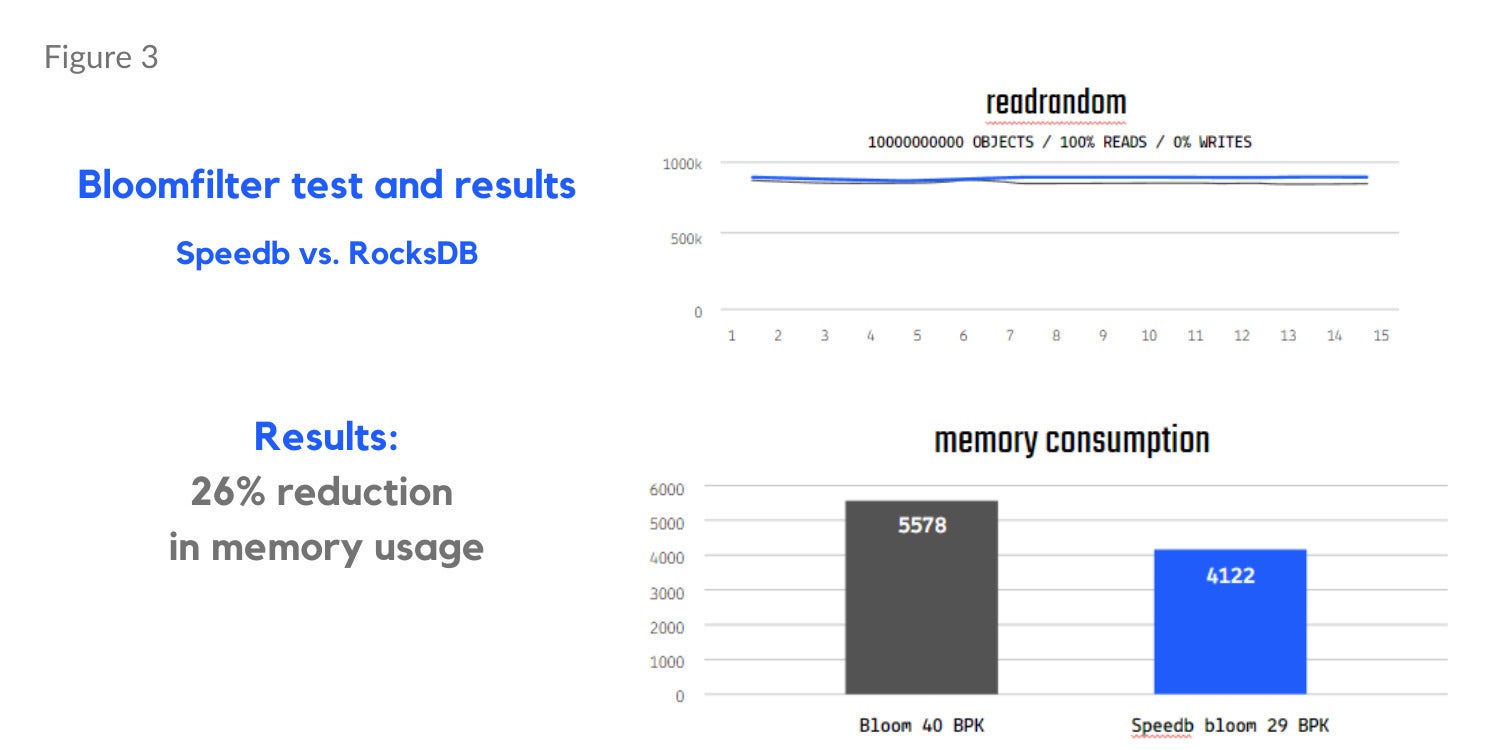
Memtable testing (Figure 1 below) shows a 17% gain in overwrite and 13% gain in mixed read and write workloads (90% reads, 10% writes). Separate bloom filter tests results show a 130% improvement in read misses in a read random workload (Figure 2) and a 26% reduction in memory usage (Figure 3).
Tests run by Redis demonstrate increased performance when Speedb replaced RocksDB in the Redis on Flash implementation. Its testing with Speedb was also agnostic to the application’s read/write ratio, indicating that performance is predictable across multiple different applications, or in applications where the access pattern varies over time.
 Speedb
SpeedbFigure 1. Memtable testing with Speedb.
 Speedb
SpeedbFigure 2. Bloom filter testing using a read random workload with Speedb.
 Speedb
SpeedbFigure 3. Bloom filter testing showing reduction in memory usage with Speedb.
Memory management
The memory management of embedded libraries plays a crucial role in application performance. Current solutions are complex and have too many intertwined parameters, making it difficult for users to optimize them for their needs. The challenge increases as the environment or workload changes.
Speedb took a holistic approach when redesigning the memory management in order to simplify the use and enhance resource utilization.
A dirty data manager allows for an improved flush scheduler, one that takes a proactive approach and improves the overall memory efficiency and system utilization, without requiring any user intervention.
Working from the ground up, Speedb is making additional features self-tunable to achieve performance, scale, and ease of use for a variety of use cases.
Flow control
Speedb redesigns RocksDB’s flow control mechanism to eliminate spikes in user latency. Its new flow control mechanism changes the rate in a manner that is far more moderate and more accurately adjusted for the system’s state than the old mechanism. It slows down when necessary and speeds up when it can. By doing so, stalls are eliminated, and the write performance is stable.
When the root cause of data engine inefficiencies is buried deep in the system, finding it might be a challenge. At the same time, the deeper the root cause, the greater the impact on the system. As the old saying goes, a chain is only as strong as its weakest link.
Next-generation data engine architectures such as Speedb can boost metadata performance, reduce latency, accelerate search time, and optimize CPU consumption. As teams expand their hyperscale applications, new data engine technology will be a critical element to enabling modern-day architectures that are agile, scalable, and performant.
Hilik Yochai is chief science officer and co-founder of Speedb, the company behind the Speedb data engine, a drop-in replacement for RocksDB, and the Hive, Speedb’s open-source community where developers can interact, improve, and share knowledge and best practices on Speedb and RocksDB. Speedb’s technology helps developers evolve their hyperscale data operations with limitless scale and performance without compromising functionality, all while constantly striving to improve the usability and ease of use.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
Copyright © 2023 IDG Communications, Inc.