
When Twitter changed hands last November I switched to Mastodon; ever since I’ve enjoyed happier and more productive social networking. To enhance my happiness and productivity I began working on a Mastodon plugin for Steampipe. My initial goal was to study the fediverse writ large. Which people and which servers are powerful connectors? How do moderation policies work? What’s it like to join a small server versus a large one?
These are important questions, and you can use the plugin to begin to answer them. But I soon realized that as a newcomer to a scene that’s been evolving for six years, and has not welcomed such analysis, I should start by looking for ways to enhance the experience of reading Mastodon. So I began building a set of dashboards that augment the stock Mastodon client or (my preference) elk.zone. And I’ve narrated that project in a series of posts.
Last week we released the plugin to the Steampipe Hub. If you’ve installed Steampipe, you can now get the plugin using steampipe plugin install mastodon. The next phases of this project will explore using the plugin and dashboards in Steampipe Cloud, and speeding up the dashboards by means of persistent Postgres tables and Steampipe Cloud snapshots. Meanwhile, here’s a recap of what I’ve learned thus far.
See more with less distraction
While the dashboards use charts and relationship graphs, they are mainly tables of query results. Because Steampipe dashboards don’t (yet) render HTML, these views display plain text only—no images, no styled text. I’ve embraced this constraint, and I find it valuable in two ways. First, I’m able to scan many more posts at a glance than is possible in conventional clients, and more effectively choose which to engage with. When I described this effect to a friend he said: “It’s a Bloomberg terminal for Mastodon!” As those of us who rode the first wave of the blogosphere will recall, RSS readers were a revelation for the same reason.
Second, I find that the absence of images and styled text has a calming effect. To maintain a healthy information diet you need to choose sources wisely but, no matter where you go, sites deploy a barrage of attention-grabbing devices. I find dialing down the noise helpful, for the same reason that I often switch my phone to monochrome mode. Attention is our scarcest resource; the fewer distractions, the better.
There’s a tradeoff, of course; sometimes an image is the entire point of a post. So while I often read Mastodon using these Steampipe dashboards, I also use Elk directly. The Steampipe dashboards work alongside conventional Mastodon clients, and indeed depend on them: I click through from the dashboards to Elk in order to boost, reply, or view images. That experience is enhanced by instance-qualified URLs that translate foreign URLs to ones that work on your home server.
Manage people and lists
The ability to assign people to lists, and read in a list-oriented way, is a handy Twitter affordance that I never used much because it was easy to let the algorithms govern my information diet. Because Mastodon doesn’t work like that, lists have become the primary way I read the fediverse flow. Of the 800+ people I follow so far, I’ve assigned more than half to lists with titles like *Climate* and *Energy* and *Software*. To help me do that, several dashboards report how many of the people I follow are assigned to lists (or not).
I want as many people on lists as possible. So I periodically review the people I follow, put unassigned people on lists, and track the ratio of people who are, or aren’t, on lists. Here’s the query for that.
with list_account as (
select
a.id,
l.title as list
from
mastodon_my_list l
join mastodon_list_account a on l.id = a.list_id
),
list_account_follows as (
select
list
from
mastodon_my_following
left join list_account using (id)
)
select 'follows listed' as label, count(*) from list_account_follows where list is not null
union
select 'follows unlisted' as label, count(*) from list_account_follows where list is null
When you read in a list-oriented away, as is also true when you read by following hashtags, there are always people whose chattiness becomes a distraction. To control that I’ve implemented the following rule: Show at most one original toot per person per list per day. Will I miss some things this way? Sure! But if you’ve said something that resonates with other people, I’m likely to hear about it from someone else. It’s a tradeoff that’s working well for me so far.
Here’s the SQL implementation of the rule.
with data as (
select
list_id,
to_char(created_at, 'YYYY-MM-DD') as day,
case
when display_name="" then username
else display_name
end as person,
instance_qualified_url as url,
substring(content from 1 for 200) as toot
from
mastodon_toot_list
where
list_id = '42994'
and reblog is null -- only original posts
and in_reply_to_account_id is null -- only original posts
limit
40
)
select
distinct on (person, day) -- only one per person per day
day,
person,
toot,
url
from
data
order by
day desc,
person;
On the home timeline’s dashboard I’ve made it optional to include or hide boosts, which can be the majority of items. On the list-reading dashboard I’ve opted to always exclude them, but the SQL idiom for doing so—select distinct on (person, day)—is simple, easy to understand, and easy to change.
Visualize relationships
I’ve so far found three ways in which relationship graphs can make Mastodon more legible. First, in Mastodon relationship graphs, I showed how to use SQL-defined nodes and edges to show boost relationships among people and servers. In another article I used the same tools to map relationships among people and tags. And most recently I used them to explore server-to-server moderation.
In all three cases the format conveys information not directly available from tabular views. Clusters of interesting people pop out, as do people who share tags. And when I graphed servers that block other servers I discovered an unexpected category: some servers that block others are themselves also blocked, like infosec.exchange in this example.
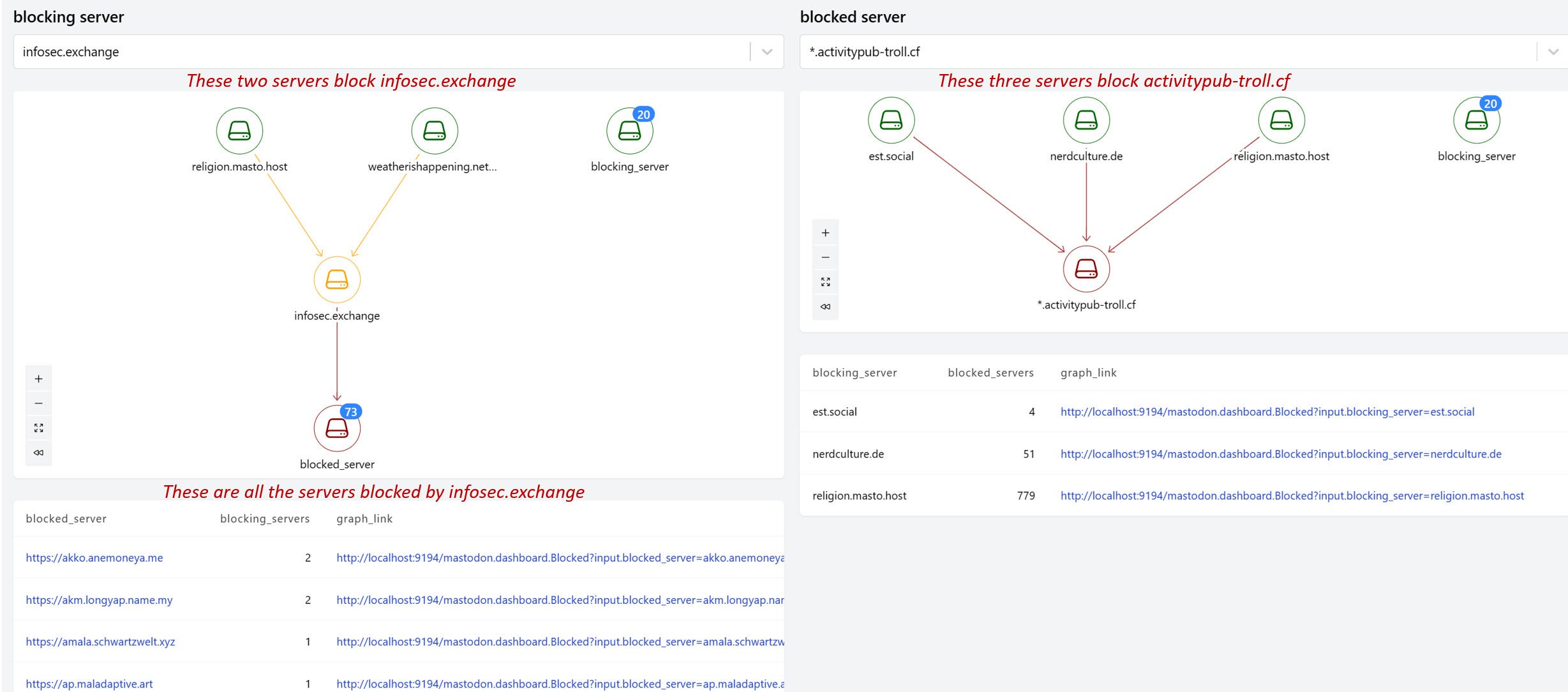 IDG
IDGThe Steampipe combo of SQL-oriented API access and dashboards as code is a uniquely productive way to build relationship graphs that can unlock insights in any domain. As we’ve seen with Kubernetes, they can help make cloud infrastructure more legible. The Mastodon graphs suggest that the same can happen in the social networking realm.
Use RSS feeds
When you append .rss to the URL of a Mastodon account, or tag, you produce an RSS feed like https://mastodon.social/@judell.rss or https://mastodon.social/tags/steampipe.rss. These feeds provide a kind of auxiliary API that includes data not otherwise available from the primary API: related tags, which appear in the feeds as RSS category elements. Steampipe really shines here thanks to the RSS plugin which enables joins with the primary Mastodon API. This query augments items in account’s feed with tags that appear in each item.
with data as (
select
name,
url || '.rss' as feed_link
from
mastodon_search_hashtag
where
query = $1,
and name = query
limit
)
select
to_char(r.published, 'YYYY-MM-DD') as published,
d.name as tag,
(
select string_agg(trim(JsonString::text, '"'), ', ')
from jsonb_array_elements(r.categories) JsonString
) as categories,
r.guid as link,
( select content as toot from mastodon_search_toot where query = r.guid ) as content
from
data d
join
rss_item r
on
r.feed_link = d.feed_link
order by
r.published desc
limit 10
A similar query drives the graph discussed in Mapping people and tags on Mastodon.
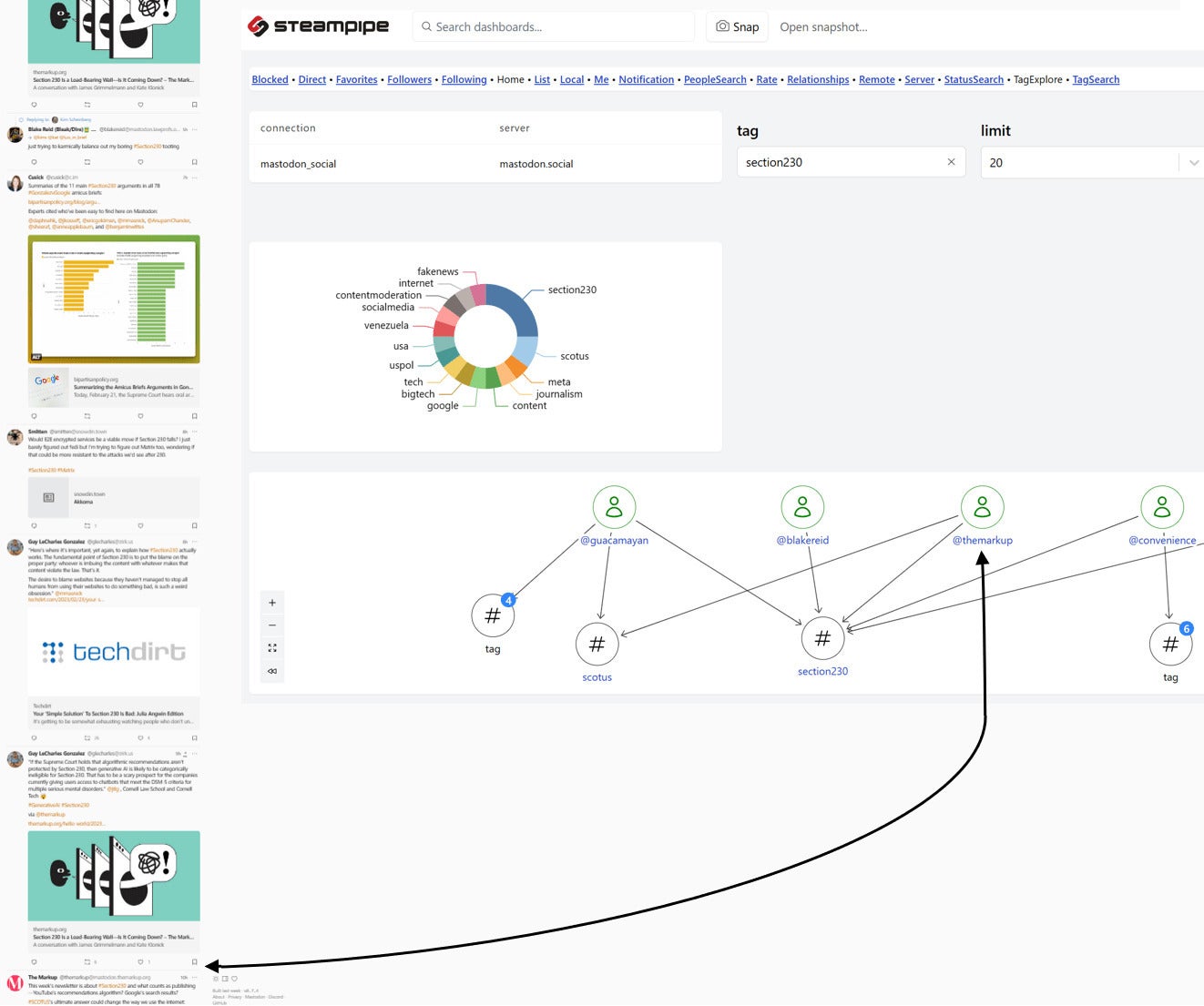 IDG
IDGIn that example, surfacing the connection between a user, @themarkup, and a pair of tags, scotus and section230, was useful in two ways. First, it helped me instantly spot the item that I most wanted to read, which was buried deep in the search results. Second, it helped me discover a source that I’ll return to for guidance on similar topics. Of course I added that source to my Law list!
Own the algorithm
Everyone who comes to Mastodon appreciates not having an adversarial algorithm control what they see in their timelines. Most of us aren’t opposed to algorithmic influence per se, though; we just don’t like the adversarial nature of it. How can we build algorithms that work with us, not against us? We’ve already seen one example: The list-reading dashboard displays just one item per list per person per day. That’s a policy that I was able to define, and easily implement, with Steampipe. And in fact I adjusted it after using it for a while. The original policy was hourly, and that was too chatty, so I switched to daily by making a trivial change to the SQL query.
In News in the fediverse I showed another example. The Mastodon server press.coop aggregates feeds from mainstream news sources. I was happy to have those feeds, but I didn’t want to see those news items mixed in with my home timeline. Rather, I wanted to assign them to a News list and read them only when I visit that list in a news-reading mindset. The fediverse offers an opportunity to reboot the social web and gain control of our information diets. Since our diets all differ, it ought to be possible—and even easy—for anyone to turn on a rule like *news only on lists, not timelines*. Steampipe can make it so.
Steampipe as component
When you ask people on Mastodon about these kinds of features, the response is often “Have you tried client X? It offers feature Y.” But that solution doesn’t scale. It would require massive duplication of effort for every client to implement every such policy; meanwhile, people don’t want to switch to client X just for feature Y (which might entail losing feature Z). Could policies be encapsulated and made available to any Mastodon client? It’s interesting to think about Steampipe as a component that delivers that encapsulation. A timeline built by SQL queries, and governed by SQL-defined policies, is a resource available to any app that can connect to Postgres, either locally or in Steampipe Cloud.
If you’re curious about the Steampipe + Mastodon combo, install the plugin, try out the sample queries, then clone the mod and check out the dashboards. Do they usefully augment your Mastodon reader? What would improve them? Can you use these ingredients to invent your own customized Mastodon experience? Join our Slack community and let us know how it goes!
This series:
- Autonomy, packet size, friction, fanout, and velocity
- Mastodon, Steampipe, and RSS
- Browsing the fediverse
- A Bloomberg terminal for Mastodon
- Create your own Mastodon UX
- Lists and people on Mastodon
- How many people in my Mastodon feed also tweeted today?
- Instance-qualified Mastodon URLs
- Mastodon relationship graphs
- Working with Mastodon lists
- Images considered harmful (sometimes)
- Mapping the wider fediverse
- Protocols, APIs, and conventions
- News in the fediverse
- Mapping people and tags in Mastodon
- Visualizing Mastodon server moderation
- Mastodon timelines for teams
- The Mastodon plugin is now available on the Steampipe Hub